This is the blog section. It has two categories: News and Releases.
Files in these directories will be listed in reverse chronological order.
This is the multi-page printable view of this section. Click here to print.
This is the blog section. It has two categories: News and Releases.
Files in these directories will be listed in reverse chronological order.
The purpose of this lab is to create a ’tiny-scale’ architecture that simulates the Zero Trust system used at Grab. Zero Trust is a security model that assumes no part of the network is secure and requires verification for every access request. This model is crucial for protecting sensitive data and ensuring secure communication between services.
Although I haven’t been part of the Grab team that set up this architecture, I have thoroughly researched their approach by studying their blog posts here. Combining this information with my own knowledge and experience, I aim to implement a similar basic workflow. This will help us understand the fundamental concepts and practices of Zero Trust security in a Kubernetes environment.
Grab uses a production-ready Kubernetes cluster to run this architecture. For this lab, I’ll use minikube as our Kubernetes environment. Minikube is an open-source tool that lets us run a single-node Kubernetes cluster locally, providing a powerful yet simplified setup perfect for development and testing. It includes many features of a full-scale Kubernetes setup but reduces the complexity, making it easier to manage and understand. Using minikube, we can create an environment that mimics a production Kubernetes cluster while remaining easy to set up and work with. You can find the CA tree that we try to implement here:
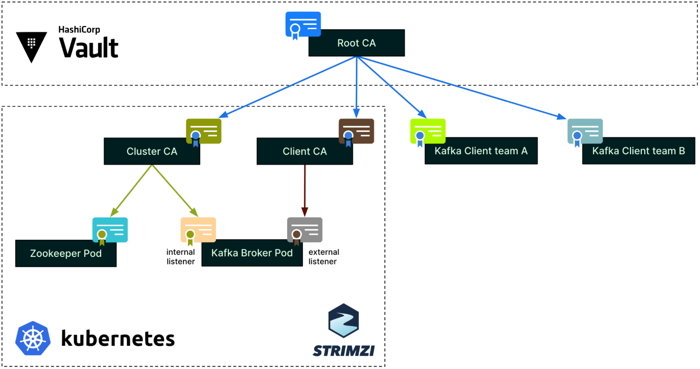
Zero Trust CA Tree at Grab
Grab’s real-time data platform team, also known as Coban, decided to use mutual Transport Layer Security (mTLS) for authentication and encryption. mTLS enables clients to authenticate servers, and servers to reciprocally authenticate clients.
They opted for Hashicorp Vault and its PKI engine to dynamically generate clients and servers’ certificates. This enables them to enforce the usage of short-lived certificates for clients, which is a way to mitigate the potential impact of a client certificate being compromised or maliciously shared.
For authorisation, they chose Policy-Based Access Control (PBAC), a more scalable solution than Role-Based Access Control (RBAC), and the Open Policy Agent (OPA) as their policy engine, for its wide community support.
To integrate mTLS and the OPA with Kafka, the Coban leveraged Strimzi, the Kafka on Kubernetes operator. They have alluded to Strimzi and hinted at how it would help with scalability and cloud agnosticism. Built-in security is undoubtedly an additional driver of their adoption of Strimzi.
minikube installed.helm installed.openssl installed.vault installed, run as client to communicate with vault cluster on minikube.Based on the points mentioned in the above sections, we can list several objectives that we should complete when we finish the lab, as follows:
In this section, we will set up a basic Vault cluster running on minikube. In the scope of this lab, we’ll keep it on the same Kubernetes cluster but run it in a separate namespace to simulate a dedicated Vault cluster, similar to what Grab uses.
First of all, we need to start our Minikube, which will be the main environment used for this lab. And then create a namespace dedicated for Vault cluster.
minikube start
kubectl create namespace vault
alias kv='kubectl -n vault' # make an alias for future queries
Add the HashiCorp Helm repository to your local Helm, then install Vault chart with default values:
helm repo add hashicorp https://helm.releases.hashicorp.com
helm repo update
helm install vault hashicorp/vault -n vault
Wait until Vault is up and running. You should see output similar to this when executing below command:
$ kv get pod,svc
NAME READY STATUS RESTARTS AGE
pod/vault-0 0/1 Running 0 40m
pod/vault-agent-injector-d986fcb9b-ckrkv 1/1 Running 0 40m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/vault ClusterIP 10.99.87.187 <none> 8200/TCP,8201/TCP 40m
service/vault-agent-injector-svc ClusterIP 10.100.251.30 <none> 443/TCP 40m
service/vault-internal ClusterIP None <none> 8200/TCP,8201/TCP 40m
The vault-0 pod is not ready yet because we haven’t unsealed Vault. First, expose the vault service so we can connect to it from our laptop. Use the minikube service feature:
$ minikube service -n vault vault
|-----------|-------|-------------|--------------|
| NAMESPACE | NAME | TARGET PORT | URL |
|-----------|-------|-------------|--------------|
| vault | vault | | No node port |
|-----------|-------|-------------|--------------|
😿 service vault/vault has no node port
🏃 Starting tunnel for service vault.
|-----------|-------|-------------|------------------------|
| NAMESPACE | NAME | TARGET PORT | URL |
|-----------|-------|-------------|------------------------|
| vault | vault | | http://127.0.0.1:57974 |
| | | | http://127.0.0.1:57975 |
|-----------|-------|-------------|------------------------|
[vault vault http://127.0.0.1:57974
http://127.0.0.1:57975]
❗ Because you are using a Docker driver on darwin, the terminal needs to be open to run it.
As the warning suggests, if you are in the same situation, open a new terminal tab and use the following command to set up the connection. Remember to note the seal key and root token from the output:
export VAULT_ADDR='http://127.0.0.1:57974'
vault operator init
Use below command or you can paste the URL to browser to unseal it directly (remember to replace your keys):
vault operator unseal <1st-unseal-key>
vault operator unseal <2nd-unseal-key>
vault operator unseal <3rd-unseal-key>
Verify the installation by checking pod:
$ kv get pod
NAME READY STATUS RESTARTS AGE
vault-0 1/1 Running 0 82m
vault-agent-injector-d986fcb9b-ckrkv 1/1 Running 0 82m
Now, we need log in to Vault using the root token noted earlier. Then, we will enable PKI engine inside Vault, and configure it as our Root CA:
vault login <root-token>
vault secrets enable -path=pki pki
# Tune the pki secrets engine to issue certificates with a maximum time-to-live (TTL)
vault secrets tune -max-lease-ttl=87600h pki
# Create Root CA
vault write -field=certificate pki/root/generate/internal \
common_name="RootCA" \
issuer_name="root-ca" \
ttl=87600h > root-ca.crt
# Role allows certificates to be issued for any CN and SAN specified in the CSRs.
vault write pki/roles/2023-servers allow_any_name=true
We are then ready for the next steps with Cluster CA and Client CA configuration.
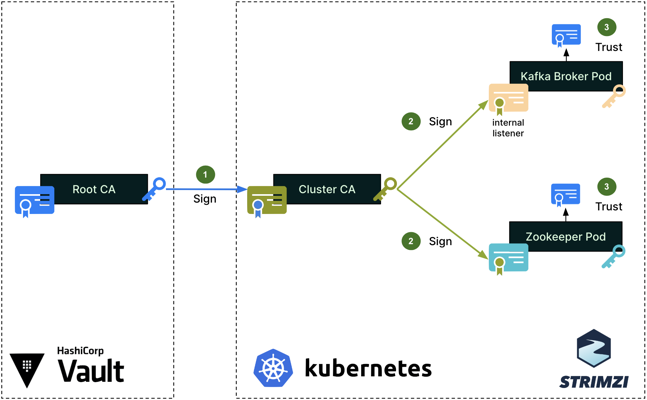
Server authentication process for internal cluster communications
To secure the cluster’s internal communications, like the communications between the Kafka broker and Zookeeper pods, Strimzi sets up a Cluster CA, which is signed by the Root CA (step 1). The Cluster CA is then used to sign the individual Kafka broker and zookeeper certificates (step 2). Lastly, the Root CA’s public certificate is imported into the truststores of both the Kafka broker and Zookeeper (step 3), so that all pods can mutually verify their certificates when authenticating one with the other.
In this scenario, Strimzi will set up a Cluster CA within the kafka namespace, and this Cluster CA certificate will be signed by the Root CA managed by Vault in the vault namespace. Instead of letting Strimzi automatically create our Cluster CA, we will generate our own key and CSR, then submit the CSR to be signed by the Root CA.
# Create key used for Cluster CA, then the CSR from the key
openssl genpkey -algorithm RSA -out cluster-ca.key -pkeyopt rsa_keygen_bits:2048
openssl req -new -key cluster-ca.key -out cluster-ca.csr -subj "/CN=ClusterCA"
# Sign the CSR with Root CA key, output include the whole chain in the certificate file
vault write -format=json pki/root/sign-intermediate \
[email protected] \
format=pem_bundle ttl="43800h" \
| jq -r '.data.certificate' > cluster-ca.crt
After the .crt and .key files are ready, we create the kafka namespace and import them as secrets stored inside the Kubernets cluster. Optionally, we can create the PKCS #12 format for the certificate if necessary.
kubectl create namespace kafka
alias kk='kubectl -n kafka' # make an alias for future queries
# We can add cluster certificate in PKCS #12 if the application support this format only
openssl pkcs12 -export -in cluster-ca.crt --nokeys -out cluster-ca.p12 -password pass:p12Password -caname cluster-ca.crt
# Create secrets for our Cluster CA cert and key
kk create secret generic tiny-cluster-ca-cert \
--from-file=ca.crt=cluster-ca.crt \
--from-file=ca.p12=cluster-ca.p12 \
--from-literal=ca.password=p12Password
kk create secret generic tiny-cluster-ca --from-file=ca.key=cluster-ca.key
We need to label and annotate the secrets so that Strimzi can use them to implement our keys and certificates in the Kafka cluster:
# Label and annotate the secrets then the strimzi can setup based on them
kk label secret tiny-cluster-ca-cert strimzi.io/kind=Kafka strimzi.io/cluster=tiny
kk label secret tiny-cluster-ca strimzi.io/kind=Kafka strimzi.io/cluster=tiny
kk annotate secret tiny-cluster-ca-cert strimzi.io/ca-cert-generation=0
kk annotate secret tiny-cluster-ca strimzi.io/ca-key-generation=0
Now, we create Strimzi’s CRDs using Helm, utilizing a custom values file (kafka/strimzi-values.yaml) to address issues related to the KUBERNETES_SERVICE_DNS_DOMAIN environment variable.
helm repo add strimzi https://strimzi.io/charts/
helm repo update
helm install strimzi-kafka strimzi/strimzi-kafka-operator --namespace kafka -f kafka/strimzi-values.yaml
Then, we can apply our Kafka cluster creation manifest:
kk apply -f kafka/kafka-cluster.yaml
Finally, we need to verify if the Cluster CA has been setup correctly:
# Export Kafka and Zookeeper certificates
kk get secret/tiny-kafka-brokers -o jsonpath='{.data.tiny-kafka-1\.crt}' | base64 -d > kafka.crt
kk get secret/tiny-zookeeper-nodes -o jsonpath='{.data.tiny-zookeeper-1\.crt}' | base64 -d > zookeeper.crt
# Veirfy the certificates
openssl verify -CAfile cluster-ca.crt kafka.crt
openssl verify -CAfile cluster-ca.crt zookeeper.crt
The command openssl verify -CAfile cluster-ca.crt zookeeper.crt is used to verify the certificate chain of the zookeeper.crt certificate against the provided Certificate Authority (CA) certificate (cluster-ca.crt) by following steps:
You should see the below output:
kafka.crt: OK
zookeeper.crt: OK
zookeeper.crt: OK: This output indicates that the verification was successful. It means:
zookeeper.crt) is indeed signed by the Cluster CA (cluster-ca.crt).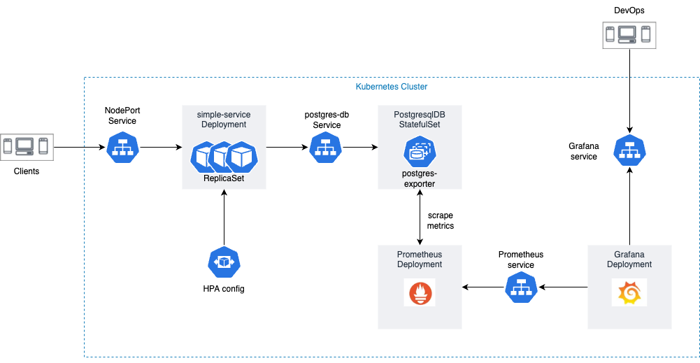
Application Infrastructure Diagram
Kubernetes has revolutionized the way we deploy and manage containerized applications, providing a scalable and resilient platform for running microservices. In this blog post, we will explore a comprehensive repository, k8s-simple-service, which showcases the deployment of a simple service, a PostgreSQL StatefulSet, and how to set up monitoring using Prometheus and Grafana. Let’s dive in and learn how to leverage Kubernetes to build and manage robust application infrastructure.
The first part of the repository focuses on deploying a simple service in Kubernetes with high availability. It provides a step-by-step guide and configuration files to create the following Kubernetes objects:
By following the instructions, you’ll be able to deploy a scalable and resilient service that can handle high traffic loads and automatically handle failovers.
In the second part of the repository, you’ll explore how to deploy a PostgreSQL StatefulSet in Kubernetes to ensure data persistence and reliability. The repository includes YAML files that define the following Kubernetes objects:
By following the provided instructions, you’ll be able to deploy a PostgreSQL database that can dynamically scale and handle data replication across multiple pods.
The final part of the repository focuses on setting up monitoring for the deployed services using Prometheus and Grafana. It includes configuration files and instructions on how to deploy the following Kubernetes objects:
By following the steps outlined in the repository, you’ll be able to gain valuable insights into the performance and health of your applications through the Prometheus and Grafana monitoring setup.
minikube cluster and install kubectl for the cluster:make infra
make build deploy
minikube service simple-service --url=true
minikube service prometheus-service --url=true
minikube service grafana --url=true
Remember to add /live after simple-service URL.
admin/admin credential to access Grafana9628 and the data-source is promethuesmake clean
The k8s-simple-service repository provides a comprehensive guide to deploying a simple service, a PostgreSQL StatefulSet, and implementing monitoring using Prometheus and Grafana in Kubernetes. By following the instructions and leveraging the provided configuration files, you can build and manage a robust and scalable application infrastructure on Kubernetes. Explore the repository, experiment with different configurations, and enhance your knowledge of Kubernetes deployment strategies and monitoring techniques.k8s
Kubespray is a popular open-source tool that makes setting up Kubernetes clusters easy. It automates the complex tasks of creating and fine-tuning a working Kubernetes cluster. It’s versatile, working for various scenarios like cloud-based setups and local servers.
This tutorial walks you through using Kubespray to smoothly install and set up a Kubernetes cluster. Kubespray uses Ansible, a powerful automation tool, to simplify the detailed steps of getting Kubernetes running.
In this tutorial, we’ll guide you through each stage, like preparing the list of computers you want in your cluster, entering your access details, and adjusting cluster settings. We’ll show you how to run an Ansible playbook that handles the whole process. It’s a hands-on journey through each step of creating your Kubernetes environment
Before you begin, make sure you have the following prerequisites:
In this post, we’ll illustrate the installation process using a specific configuration: 1 master node and 2 worker nodes. This example will guide you through the steps required to set up this particular arrangement of nodes, offering a clear and practical demonstration of the installation procedure.
Setting up SSH for Ansible involves establishing a secure and reliable connection between your Ansible control machine (the one you’re running Ansible commands from) and the target hosts you want to manage. Here’s a step-by-step guide on how to set up SSH for Ansible.
If you haven’t already, generate an SSH key pair on your Ansible control machine:
ssh-keygen -t rsa
Copy the public key (~/.ssh/id_rsa.pub) from your Ansible control machine to the target hosts. You can use tools like ssh-copy-id:
ssh-copy-id username@target_host
Replace username with the username you want to use for SSH access and target_host with the hostname or IP address of the target host. You might need to enter the password for the target host.
Test that you can SSH into the remote hosts without needing to enter a password:
ssh remote_user@target_host
This should log you in without asking for a password.
Kubespray supports multiple ansible versions and ships different requirements.txt files for them. Depending on your available python version you may be limited in choosing which ansible version to use.
It is recommended to deploy the ansible version used by kubespray into a python virtual environment.
VENVDIR=kubespray-venv
python3 -m venv $VENVDIR
source $VENVDIR/bin/activate
pip install -U -r requirements.txt
In case you have a similar message when installing the requirements:
ERROR: Could not find a version that satisfies the requirement ansible==7.6.0 (from -r requirements.txt (line 1)) (from versions: [...], 6.7.0)
ERROR: No matching distribution found for ansible==7.6.0 (from -r requirements.txt (line 1))
It means that the version of Python you are running is not compatible with the version of Ansible that Kubespray supports. If the latest version supported according to pip is 6.7.0 it means you are running Python 3.8 or lower while you need at least Python 3.9 (see the table below).
| Ansible Version | Python Version |
|---|---|
| 2.14 | 3.9-3.11 |
First, clone the Kubespray repository to your local machine:
git clone https://github.com/kubernetes-sigs/kubespray.git
cd kubespray
Ansible inventory can be stored in 3 formats: YAML, JSON, or INI-like.
You can use an inventory generator to create or modify an Ansible inventory. Currently, it is limited in functionality and is only used for configuring a basic Kubespray cluster inventory, but it does support creating inventory file for large clusters as well. It now supports separated ETCD and Kubernetes control plane roles from node role if the size exceeds a certain threshold. Run python3 contrib/inventory_builder/inventory.py help for more information.
Example inventory generator usage:
cp -r inventory/sample inventory/mycluster
declare -a IPS=(192.168.1.11 192.168.1.21 192.168.1.22)
CONFIG_FILE=inventory/mycluster/hosts.yml KUBE_CONTROL_HOSTS=1 python3 contrib/inventory_builder/inventory.py ${IPS[@]}
Then use inventory/mycluster/hosts.yml as inventory file.
The main client of Kubernetes is kubectl. It is installed on each kube_control_plane host and can optionally be configured on your ansible host by setting kubectl_localhost: true and kubeconfig_localhost: true in the configuration:
kubectl_localhost enabled, kubectl will download onto /usr/local/bin/ and setup with bash completion. A helper script inventory/mycluster/artifacts/kubectl.sh also created for setup with below admin.conf.kubeconfig_localhost enabled admin.conf will appear in the inventory/mycluster/artifacts/ directory after deployment.artifacts_dir variable.NOTE: The controller host name in the admin.conf file might be a private IP. If so, change it to use the controller’s public IP or the cluster’s load balancer.
Once you have an inventory, you may want to customize deployment data vars and start the deployment
Modify the inventory/my-cluster/group_vars/all/all.yml file to configure various parameters for your Kubernetes cluster. Pay attention to settings like kube_network_plugin, kube_version, and others according to your preferences.
ansible-playbook -i inventory/mycluster/hosts.yml cluster.yml -b -v \
--private-key=~/.ssh/id_rsa \
--extra-vars "ansible_sudo_pass=your_sudo_passwd"
The installation process might take some time, depending on your machine’s resources and network speed.
You can see a list of nodes by running the following commands:
cd inventory/mycluster/artifacts
./kubectl.sh get nodes
If desired, copy admin.conf to ~/.kube/config.
Kubespray simplifies the process of setting up and configuring Kubernetes clusters, making it easier for DevOps teams to manage their infrastructure. In this tutorial, we covered the basic steps to install Kubernetes using Kubespray. You can now explore more advanced configurations and features to customize your cluster according to your project’s needs.
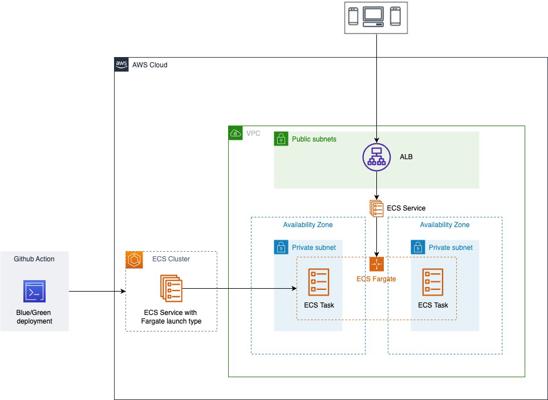
Overview of the AWS infrastructure
In recent years, containerization has gained immense popularity due to its ability to simplify deployment and management of applications. Amazon Elastic Container Service (ECS) is a fully managed container orchestration service that allows you to easily run and scale containerized applications on AWS. To streamline the provisioning of ECS infrastructure, the open-source community has developed various tools, with Terraform and Terragrunt being one of the most powerful combinations.
In this blog post, we will explore a comprehensive Terraform and Terragrunt repository, terraform-aws-ecs-sample-infra, which provides a robust foundation for building scalable ECS infrastructure on AWS. Let’s dive in and see how it can help us accelerate our ECS deployments.
Terraform is an infrastructure as code (IaC) tool that allows you to define and provision infrastructure resources using declarative configuration files. By leveraging Terraform, you can automate the creation, modification, and destruction of infrastructure, making it easier to manage complex systems.
Terragrunt, an open-source tool, provides additional functionalities and improvements for managing Terraform configurations. It simplifies the management of infrastructure code by enabling code reuse, remote state management, and dependency management between Terraform modules.
Authenticate your AWS client with enironment variable:
export AWS_ACCESS_KEY_ID=AKIAIOSFODNN7EXAMPLE
export AWS_SECRET_ACCESS_KEY=xxxxxxxxxxxxxx
export AWS_DEFAULT_REGION=us-west-2
Authenticate your Docker client to the Amazon ECR repository
aws ecr get-login-password --region region | docker login --username AWS --password-stdin aws_account_id.dkr.ecr.region.amazonaws.com
Use docker images to identify the local image to push, then push it:
docker tag nginx:latest public.ecr.aws/xxxxxxxx/nginx:v0.1.0
docker push public.ecr.aws/xxxxxxxx/nginx:v0.1.0
Create your environment settings in file envVars.yaml, for example:
env: "dev"
vpcCIDR: "10.0.0.0/16"
privateSubnets:
- "10.0.1.0/24"
- "10.0.2.0/24"
publicSubnets:
- "10.0.3.0/24"
- "10.0.4.0/24"
availabilityZones:
- "ap-southeast-1a"
- "ap-southeast-1b"
imageURI: "public.ecr.aws/k2u4r9u5/nginx:v0.1.0"
containerPort: 443
For deploy your entire infrastructure, in the terragrunt root directory, run:
terragrunt run-all apply
The repository offers a flexible and customizable infrastructure setup. You can easily modify the configuration files to adapt to your specific application requirements. For example, you can adjust the number of subnets or change the load balancer type based on your traffic patterns.
By leveraging Terraform’s module structure and Terragrunt’s features, you can extend the repository with additional modules, customize environment-specific configurations, and manage dependencies between modules. This modular and hierarchical approach makes it convenient to enhance and expand your infrastructure without starting from scratch.
The terraform-aws-ecs-sample-infra repository serves as an excellent starting point for building scalable infrastructure for AWS ECS deployments using Terraform and Terragrunt. It provides a well-structured, modular, and reusable setup that simplifies the provisioning and management of ECS resources on AWS.
By leveraging the power of Terraform and Terragrunt, you can accelerate your development workflow, ensure consistent and reliable infrastructure.
Throughout this blog post, we will explore the code and functionality of these files in detail. By following the steps provided, you can deploy and experience the power of the multi-workflow application built using the AWS Serverless Application Model.
For a comprehensive view of the code discussed throughout this blog post, please refer to the complete set of code available here.
The AWS Serverless Application Model (AWS SAM) is a toolkit that improves the developer experience of building and running serverless applications on AWS. AWS SAM consists of two primary parts:
AWS SAM template specification – An open-source framework that you can use to define your serverless application infrastructure on AWS.
AWS SAM command line interface (AWS SAM CLI) – A command line tool that you can use with AWS SAM templates and supported third-party integrations to build and run your serverless applications.
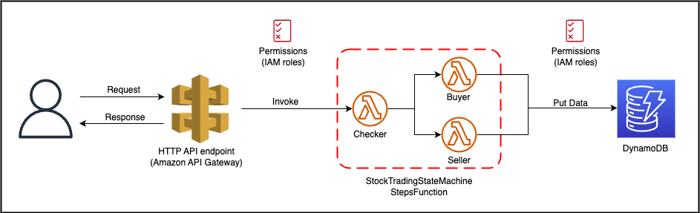
This project contains source code and supporting files for a serverless application that you can deploy with the SAM CLI. It includes the following files and folders:
samconfig.toml file is a configuration file used by the SAM CLI. It allows you to specify deployment parameters such as the AWS Region, the deployment bucket name, and other settings.This application creates a mock stock trading workflow which runs on a pre-defined schedule (note that the schedule is disabled by default to avoid incurring charges). It demonstrates the power of Step Functions to orchestrate Lambda functions and other AWS resources to form complex and robust workflows, coupled with event-driven development using Amazon EventBridge.
AWS Step Functions lets you coordinate multiple AWS services into serverless workflows so you can build and update apps quickly. Using Step Functions, you can design and run workflows that stitch together services, such as AWS Lambda, AWS Fargate, and Amazon SageMaker, into feature-rich applications.
The application uses several AWS resources, including Step Functions state machines, Lambda functions and an EventBridge rule trigger. These resources are defined in the template.yaml file in this project. You can update the template to add AWS resources through the same deployment process that updates your application code.
To build and deploy your application for the first time, run the following in your shell:
sam build
sam deploy --guided
The first command will build the source of your application. The second command will package and deploy your application to AWS, with a series of prompts:
CAPABILITY_IAM value for capabilities must be provided. If permission isn’t provided through this prompt, to deploy this example you must explicitly pass --capabilities CAPABILITY_IAM to the sam deploy command.sam deploy without parameters to deploy changes to your application.To delete the sample application that you created, use the AWS CLI. Assuming you used your project name for the stack name, you can run the following:
sam delete --stack-name "sam-app"
See the AWS SAM developer guide for an introduction to SAM specification, the SAM CLI, and serverless application concepts.
Next, you can use AWS Serverless Application Repository to deploy ready to use Apps that go beyond hello world samples and learn how authors developed their applications: AWS Serverless Application Repository main page
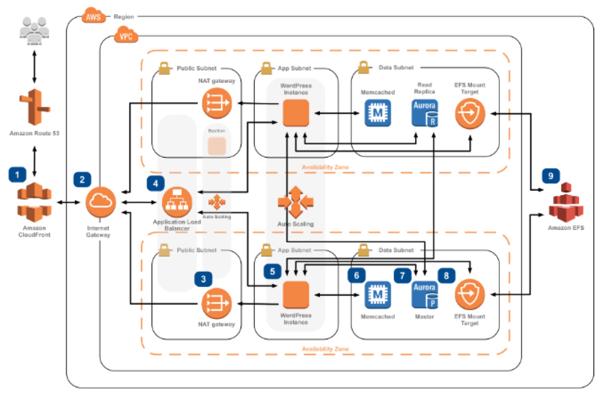
Overview of the AWS infrastructure
In today’s digital landscape, high availability is a critical requirement for web applications to ensure seamless user experiences and minimize downtime. Amazon Web Services (AWS) provides a robust infrastructure to build highly available web applications, and with the power of Terraform, automating the provisioning of such infrastructure becomes even easier.
In this blog post, we will explore a comprehensive Terraform repository, terraform-aws-ha-webapp, that offers a scalable and fault-tolerant architecture for deploying a highly available web application on AWS. Let’s dive in and see how this repository can help us build resilient web applications.
Terraform is an infrastructure as code (IaC) tool that enables you to define and provision infrastructure resources using declarative configuration files. It simplifies the process of managing infrastructure, allowing you to automate the creation, modification, and destruction of resources.
The terraform-aws-ha-webapp repository follows a well-organized structure that separates different components of the infrastructure. It includes modules for the web application, load balancers, auto scaling groups, databases, and more. This modular approach allows for easy customization and scalability.
The repository offers several features and benefits for building a highly available web application:
High Availability: The architecture incorporates redundancy and fault tolerance at multiple layers to ensure high availability of the application, even in the face of failures.
Auto Scaling: The web application is set up with auto scaling groups, allowing it to automatically scale up or down based on demand, ensuring optimal performance and cost efficiency.
Load Balancing: The application is fronted by an Elastic Load Balancer (ELB) that distributes incoming traffic across multiple instances, improving performance and enabling seamless handling of traffic spikes.
Database Resilience: The repository includes options for setting up highly available databases, such as Amazon RDS with Multi-AZ deployment or Amazon Aurora.
Security: The infrastructure incorporates security best practices, such as using AWS Identity and Access Management (IAM) roles, security groups, and SSL certificates to protect the application and its data.
Here is some related components to follow my scanerio:
Clone the repository:
git clone https://github.com/tigonguyen/terraform-basic-web-app.git
cd terraform-basic-web-app/envs/
Provision S3 andf DynamoDB backend:
cd backend
terraform init
terraform plan --out "tfplan"
terraform apply "tfplan"
cd ../
Provision a new HA web environment via modifying a yaml file:
cp -rf dev uat
cd uat/
sed -i 's/dev/uat/g' env_vars.yaml \
&& sed -i 's+10.0.0.0/16+192.168.0.0/16+g' env_vars.yaml \
&& sed -i 's+10.0.0.0/24+192.168.0.0/24+g' env_vars.yaml \
&& sed -i 's+10.0.1.0/24+192.168.1.0/24+g' env_vars.yaml \
&& sed -i 's+10.0.2.0/24+192.168.2.0/24+g' env_vars.yaml \
&& sed -i 's+10.0.3.0/24+192.168.3.0/24+g' env_vars.yaml \
&& sed -i 's+10.0.5.0/24+192.168.4.0/24+g' env_vars.yaml \
&& sed -i 's+10.0.5.0/24+192.168.5.0/24+g' env_vars.yaml
Provision entire the architecture:
terragrunt run-all apply
Clean up:
terragrunt run-all destroy
The terraform-aws-ha-webapp repository offers a powerful solution for building highly available web applications on AWS using Terraform. With its modular architecture, scalability, and fault tolerance features, you can confidently deploy resilient web applications that provide exceptional user experiences and minimize downtime.
By leveraging the capabilities of Terraform, you can automate the provisioning and management of your infrastructure, enabling faster development cycles and reducing the risk of configuration drift. Give it a try and take your web application deployments to the next level!
Start building your highly available web application with Terraform and the terraform-aws-ha-webapp repository today.
Happy coding!
In the ever-evolving landscape of database technologies, NoSQL databases have become increasingly popular due to their flexibility, scalability, and ability to handle diverse data structures. However, with this flexibility comes the critical challenge of implementing robust access control mechanisms. This article summarizes a comprehensive study on access control implementations across various NoSQL databases and provides detailed insights into common vulnerabilities and their fixes.
The study, available at GitHub Repository, focuses on analyzing and comparing access control mechanisms in popular NoSQL databases. The research aims to provide insights into security models, implementation patterns, and best practices for securing NoSQL database systems.
NoSQL databases typically implement one or more of the following access control models:
Role-Based Access Control (RBAC)
Attribute-Based Access Control (ABAC)
Document-Level Security
Common patterns observed across different NoSQL databases include:
Vulnerability: MongoDB provides access control at the database and collection levels but lacks native support for field-level access control. This means users can access entire collections, which may expose sensitive data.
Fix: Implement application-level access control by embedding access policies within documents. This allows for field-level security by specifying which roles can access certain fields.
db.employees.updateMany({}, [
{
$set: {
accessPolicy: {
salary: { role: ["hrUser"] }, // Only hrUser can see salary
name: { role: ["hrUser", "regularUser"] },
department: { role: ["hrUser", "regularUser"] },
role: { role: ["hrUser"] }
}
}
}
]);
Vulnerability: Neo4j Community Edition does not support fine-grained access control, leading to over-permissioning where users can access more data than intended.
Fix: Implement application-level access control by using role-based access control in the application code.
class EmployeeAccessControl:
def __init__(self, uri, user, password):
self.driver = GraphDatabase.driver(uri, auth=(user, password))
def get_employee_data(self, user_role):
with self.driver.session() as session:
if user_role == "Manager":
result = session.run("""
MATCH (e:Employee)-[:HAS_SALARY]->(s:Salary)
RETURN e.name, e.role, s.amount
""")
else:
result = session.run("""
MATCH (e:Employee)-[:WORKS_IN]->(d:Department)
RETURN e.name, e.role, d.name
""")
return result
Vulnerability: MongoDB is vulnerable to NoSQL injection if user inputs are not properly sanitized. An attacker can manipulate queries to access or modify data.
Fix: Sanitize and validate user inputs before using them in queries. Use regular expressions to ensure only valid inputs are accepted.
def sanitize_input(user_input):
if re.match("^[a-zA-Z]+$", user_input): # Only allow alphabetic names
return user_input
else:
raise ValueError("Invalid input: only alphabetic characters allowed")
def secure_find_employee(user_input):
sanitized_input = sanitize_input(user_input)
employees = db.employees.find({"name": sanitized_input})
return list(employees)
Vulnerability: Neo4j is vulnerable to injection attacks if user inputs are directly used in queries without sanitization.
Fix: Use parameterized queries to safely handle user inputs, preventing injection attacks.
class EmployeeSearch:
def __init__(self, uri, user, password):
self.driver = GraphDatabase.driver(uri, auth=(user, password))
def search_employee_by_name(self, user_input):
with self.driver.session() as session:
result = session.run(
"MATCH (e:Employee {name: $name}) RETURN e.name, e.role",
name=user_input # Safe parameter binding
)
return result
Vulnerability: MongoDB’s audit logging is not enabled by default, which can make it difficult to track database activity and detect unauthorized access.
Fix: Enable profiling to capture all operations, which helps in monitoring and auditing database activities.
use companyDB;
db.setProfilingLevel(2); // Captures all operations
Vulnerability: Neo4j Community Edition lacks built-in audit logging, making it difficult to track user actions.
Fix: Use Neo4j Enterprise Edition to enable audit logging, which provides detailed logs of database activities.
version: '3'
services:
neo4j:
image: neo4j:enterprise
environment:
- NEO4J_AUTH=neo4j/password
- NEO4J_ACCEPT_LICENSE_AGREEMENT=yes
ports:
- "7474:7474"
- "7687:7687"
Configure audit logging in neo4j.conf:
db.logs.query.enabled=INFO
db.logs.query.threshold=0
Principle of Least Privilege
Role Management
Authentication
Monitoring and Auditing
Access control in NoSQL databases requires careful consideration of security requirements, performance implications, and maintenance overhead. As demonstrated in the vulnerability and fix examples, implementing proper access control mechanisms is crucial for protecting sensitive data in NoSQL databases while maintaining their flexibility and performance benefits.
This article is part of our ongoing series on database security and best practices. For more information, please refer to the original research repository.
Thinking about starting your very own blog? That’s a fantastic idea! In this beginner-friendly guide, we’ll walk you through the process of creating a blog using Hugo (a user-friendly website builder) and hosting it on Cloudflare Pages. Don’t worry if you’re not a tech whiz; we’re here to make this easy and fun for you.
Before we begin, here’s what you’ll need:
Go to the Hugo website and download Hugo for your computer’s operating system (Windows, macOS, or Linux).
Follow the installation instructions on their website – it’s like installing any other program.
Now that you have Hugo installed, let’s create your blog:
Open your computer’s command prompt or terminal.
Type hugo new site myblog (replace ‘myblog’ with your desired blog name) and press Enter. This creates a new Hugo site.
Choose a theme for your blog by finding one you like on the Hugo Themes website.
Download your chosen theme and follow the theme’s instructions to install it.
You’re ready to start adding content to your blog:
Create a new blog post by typing hugo new posts/my-first-post.md in your command prompt or terminal.
Open the file my-first-post.md and start writing your blog post in simple Markdown (a plain text format).
Save your post.
To see how your blog looks, run hugo server in your terminal and visit http://localhost:1313 in your web browser.
Deploying Your Hugo Site to Cloudflare Pages in Four Main Steps
That’s it! Your Hugo blog will be live on Cloudflare Pages once the deployment is complete.
You’ve successfully set up your blog using Hugo and hosted it on Cloudflare Pages! This is just the beginning of your blogging journey. Keep writing, customizing, and growing your blog.
If you’re working on multiple repositories based on your work and personal projects. And you need to seperate gitconfig usernames and emails for each of scope, for example to show up your contributions on personal GitHub profile.
So, this post is for you!
First, you need to put whole repositories from each scope inside a distint directory. It help git recognizes which type of project you’re working on when doing git operations, then uses the corresponding gitconfig profile.
For example, let’s say that you may want to seperate your work and personal workspaces:
~/git-repos/personal-projects/ → For personal projects.~/git-repos/work-projects/ → For work projects..gitconfigCreate the global .gitconfig file in your home directory if it doesn’t exist. Then add the below to the file:
[includeIf "gitdir:~/git-repos/personal-projects/*/"]
path = ~/.gitconfig-personal
[includeIf "gitdir:~/git-repos/work-projects/*/"]
path = ~/.gitconfig-work
With this configuration, if the path where you created the git directory matches one of the paths in inclideIF, then the corresponding configuration file will be used.
.gitconfig for each scopeIf you haven’t noticed by now, we just mentioned the .gitconfig-personal and .gitconfig-work files in the global .gitconfig file, but we didn’t create them yet. These individual files can contain all the customization that you need, from user name and email to commit hooks.
Add this to .gitconfig-work file from your home directory:
[user]
name = work_username
email = [email protected]
And add this to .gitconfig-personal file
[user]
name = personal_username
email = [email protected]
We’re all set! Now we will create and initiate a new git repository in the personal workspace and check the configurations.
cd ~/git-repos/personal-projects/
mkdir personal-test-repo
cd personal-test-repo
git init
Then you can validate your work with git config -l, the result should be like this:
$ git init
*Initialized empty Git repository in ~/git-repos/personal-projects/personal-test-repo/.git/*
$ git config -l
...
user.name=personal_username
[email protected]
...