Run a Simple Service with Observability on Kubernetes
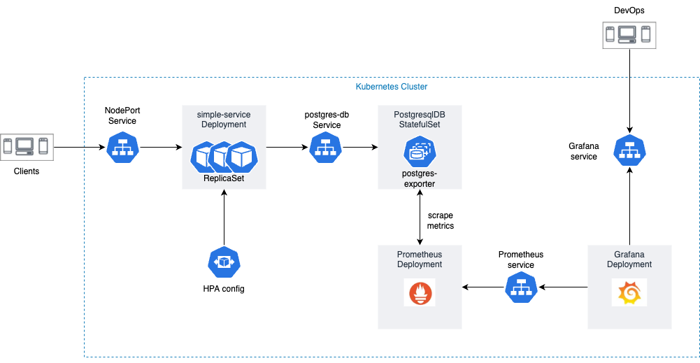
Application Infrastructure Diagram
Kubernetes has revolutionized the way we deploy and manage containerized applications, providing a scalable and resilient platform for running microservices. In this blog post, we will explore a comprehensive repository, k8s-simple-service, which showcases the deployment of a simple service, a PostgreSQL StatefulSet, and how to set up monitoring using Prometheus and Grafana. Let’s dive in and learn how to leverage Kubernetes to build and manage robust application infrastructure.
Deploying a Simple Service with High Availability
The first part of the repository focuses on deploying a simple service in Kubernetes with high availability. It provides a step-by-step guide and configuration files to create the following Kubernetes objects:
- Deployment: Defines the desired state for the simple service and manages the pods running the service.
- Service: Exposes the simple service within the Kubernetes cluster, allowing other services to access it.
- Ingress: Configures external access to the service by routing incoming traffic based on specified rules.
By following the instructions, you’ll be able to deploy a scalable and resilient service that can handle high traffic loads and automatically handle failovers.
PostgreSQL StatefulSet for Data Persistence
In the second part of the repository, you’ll explore how to deploy a PostgreSQL StatefulSet in Kubernetes to ensure data persistence and reliability. The repository includes YAML files that define the following Kubernetes objects:
- StatefulSet: Manages the deployment and scaling of the PostgreSQL database pods, ensuring stable network identities and persistent storage for each pod.
- Headless Service: Provides a network identity for the StatefulSet pods, allowing them to communicate with each other.
- Persistent Volume Claim: Requests and binds persistent storage for each PostgreSQL pod, ensuring data persistence across pod restarts or rescheduling.
By following the provided instructions, you’ll be able to deploy a PostgreSQL database that can dynamically scale and handle data replication across multiple pods.
Monitoring with Prometheus and Grafana
The final part of the repository focuses on setting up monitoring for the deployed services using Prometheus and Grafana. It includes configuration files and instructions on how to deploy the following Kubernetes objects:
- Prometheus Deployment: Deploys the Prometheus monitoring system, which collects and stores metrics from the Kubernetes cluster and the deployed services.
- Grafana Deployment: Deploys the Grafana visualization tool, which provides a user-friendly interface for querying and visualizing metrics stored in Prometheus.
- ServiceMonitor: Defines the monitoring targets and metrics to be scraped by Prometheus, enabling monitoring of the deployed services.
By following the steps outlined in the repository, you’ll be able to gain valuable insights into the performance and health of your applications through the Prometheus and Grafana monitoring setup.
Usage
- Start the
minikubecluster and installkubectlfor the cluster:
make infra
- Build and deploy the app:
make build deploy
- Run every single below commands in 3 different terminals to get services’ link:
minikube service simple-service --url=true
minikube service prometheus-service --url=true
minikube service grafana --url=true
Remember to add /live after simple-service URL.
- Configure Grafana
- Using
admin/admincredential to access Grafana - Import Postgres dashboard with the ID is
9628and the data-source ispromethues
- Clean the infrastruture:
make clean
Conclusion
The k8s-simple-service repository provides a comprehensive guide to deploying a simple service, a PostgreSQL StatefulSet, and implementing monitoring using Prometheus and Grafana in Kubernetes. By following the instructions and leveraging the provided configuration files, you can build and manage a robust and scalable application infrastructure on Kubernetes. Explore the repository, experiment with different configurations, and enhance your knowledge of Kubernetes deployment strategies and monitoring techniques.k8s
Install Kubernetes Cluster using Kubespray
Kubespray is a popular open-source tool that makes setting up Kubernetes clusters easy. It automates the complex tasks of creating and fine-tuning a working Kubernetes cluster. It’s versatile, working for various scenarios like cloud-based setups and local servers.
This tutorial walks you through using Kubespray to smoothly install and set up a Kubernetes cluster. Kubespray uses Ansible, a powerful automation tool, to simplify the detailed steps of getting Kubernetes running.
In this tutorial, we’ll guide you through each stage, like preparing the list of computers you want in your cluster, entering your access details, and adjusting cluster settings. We’ll show you how to run an Ansible playbook that handles the whole process. It’s a hands-on journey through each step of creating your Kubernetes environment
Prerequisites
Before you begin, make sure you have the following prerequisites:
- One or more machines running a deb/rpm-compatible Linux OS; for example: Ubuntu or CentOS.
- 2 GiB or more of RAM per machine–any less leaves little room for your apps.
- At least 2 CPUs on the machine that you use as a control-plane node.
- Full network connectivity among all machines in the cluster. You can use either a public or a private network.
In this post, we’ll illustrate the installation process using a specific configuration: 1 master node and 2 worker nodes. This example will guide you through the steps required to set up this particular arrangement of nodes, offering a clear and practical demonstration of the installation procedure.
Initialize the environment
Step 1.1: Initialize SSH connection
Setting up SSH for Ansible involves establishing a secure and reliable connection between your Ansible control machine (the one you’re running Ansible commands from) and the target hosts you want to manage. Here’s a step-by-step guide on how to set up SSH for Ansible.
If you haven’t already, generate an SSH key pair on your Ansible control machine:
ssh-keygen -t rsa
Copy the public key (~/.ssh/id_rsa.pub) from your Ansible control machine to the target hosts. You can use tools like ssh-copy-id:
ssh-copy-id username@target_host
Replace username with the username you want to use for SSH access and target_host with the hostname or IP address of the target host. You might need to enter the password for the target host.
Test that you can SSH into the remote hosts without needing to enter a password:
ssh remote_user@target_host
This should log you in without asking for a password.
Step 1.2: Installing Ansible
Kubespray supports multiple ansible versions and ships different requirements.txt files for them. Depending on your available python version you may be limited in choosing which ansible version to use.
It is recommended to deploy the ansible version used by kubespray into a python virtual environment.
VENVDIR=kubespray-venv
python3 -m venv $VENVDIR
source $VENVDIR/bin/activate
pip install -U -r requirements.txt
In case you have a similar message when installing the requirements:
ERROR: Could not find a version that satisfies the requirement ansible==7.6.0 (from -r requirements.txt (line 1)) (from versions: [...], 6.7.0)
ERROR: No matching distribution found for ansible==7.6.0 (from -r requirements.txt (line 1))
It means that the version of Python you are running is not compatible with the version of Ansible that Kubespray supports. If the latest version supported according to pip is 6.7.0 it means you are running Python 3.8 or lower while you need at least Python 3.9 (see the table below).
| Ansible Version | Python Version |
|---|---|
| 2.14 | 3.9-3.11 |
Install the kubernetes cluster
Step 2.1: Clone Kubespray Repository
First, clone the Kubespray repository to your local machine:
git clone https://github.com/kubernetes-sigs/kubespray.git
cd kubespray
Step 2.2: Configure Inventory
Ansible inventory can be stored in 3 formats: YAML, JSON, or INI-like.
You can use an inventory generator to create or modify an Ansible inventory. Currently, it is limited in functionality and is only used for configuring a basic Kubespray cluster inventory, but it does support creating inventory file for large clusters as well. It now supports separated ETCD and Kubernetes control plane roles from node role if the size exceeds a certain threshold. Run python3 contrib/inventory_builder/inventory.py help for more information.
Example inventory generator usage:
cp -r inventory/sample inventory/mycluster
declare -a IPS=(192.168.1.11 192.168.1.21 192.168.1.22)
CONFIG_FILE=inventory/mycluster/hosts.yml KUBE_CONTROL_HOSTS=1 python3 contrib/inventory_builder/inventory.py ${IPS[@]}
Then use inventory/mycluster/hosts.yml as inventory file.
Step 2.3: Configure for accessing Kubernetes API
The main client of Kubernetes is kubectl. It is installed on each kube_control_plane host and can optionally be configured on your ansible host by setting kubectl_localhost: true and kubeconfig_localhost: true in the configuration:
- If
kubectl_localhostenabled,kubectlwill download onto/usr/local/bin/and setup with bash completion. A helper scriptinventory/mycluster/artifacts/kubectl.shalso created for setup with belowadmin.conf. - If
kubeconfig_localhostenabledadmin.confwill appear in theinventory/mycluster/artifacts/directory after deployment. - The location where these files are downloaded to can be configured via the
artifacts_dirvariable.
NOTE: The controller host name in the admin.conf file might be a private IP. If so, change it to use the controller’s public IP or the cluster’s load balancer.
Step 2.4: Start the custom deployment
Once you have an inventory, you may want to customize deployment data vars and start the deployment
Modify the inventory/my-cluster/group_vars/all/all.yml file to configure various parameters for your Kubernetes cluster. Pay attention to settings like kube_network_plugin, kube_version, and others according to your preferences.
ansible-playbook -i inventory/mycluster/hosts.yml cluster.yml -b -v \
--private-key=~/.ssh/id_rsa \
--extra-vars "ansible_sudo_pass=your_sudo_passwd"
The installation process might take some time, depending on your machine’s resources and network speed.
Step 2.5: Verify the cluster
You can see a list of nodes by running the following commands:
cd inventory/mycluster/artifacts
./kubectl.sh get nodes
If desired, copy admin.conf to ~/.kube/config.
Conclusion
Kubespray simplifies the process of setting up and configuring Kubernetes clusters, making it easier for DevOps teams to manage their infrastructure. In this tutorial, we covered the basic steps to install Kubernetes using Kubespray. You can now explore more advanced configurations and features to customize your cluster according to your project’s needs.